
개요(오래된 하드웨어들)
컴퓨터의 발전과 함께 수많은 하드웨어가 등장했습니다.
초기 컴퓨터인 에니악(ENIAC)을 개발하며 발견한 단점을 개선에 폰 노이만 구조가 등장했고
이후 에드삭(EDSAC)부터는 폰 노이만 구조를 사용했습니다.
CPU와 주기억장치, I/O장치로 컴퓨터가 세분화되었고 지금의 컴퓨터도 이러한 구조를 채택하고 있습니다.
이후 CPU처리량과 주기억장치 간 속도 차이를 해결하기 위한 CPU캐시가 등장했고, CPU처리량과 주기억장치 용량이 커짐으로 컴퓨터에 대용량 자료를 적재해야 할 상황이 생기자, 이를 해결하기 위해 보조기억장치가 등장했습니다.
반도체는 기본적으로 속도가 빠를수록 가격이 비싸지고, 보조기억장치는 주기억장치보다 저렴한 가격에 많은 자료를 적재할 수 있었습니다.
이 때문에 컴퓨터에 주기억장치보다 큰 용량의 프로그램을 적재하고 실행할 수 있었고, 이는 가상메모리 기술로 이어집니다.
또, IO장치와 주기억장치 간의 병목현상을 개선하기 위해 BUS개념이 도입되었습니다.

10년~20년 전의 메인보드를 보면 North bridge, South bridge라는 친구들이 있습니다. 이러한 부품이 각각 CPU, 주기억장치를 관리하는 버스, 비교적 느린 하드웨어인 IO를 관리하는 버스였습니다.
이렇게 컴퓨터에 탑재되는 하드웨어들은 각자의 필요성에 따라 부품이 추가되거나 통합, 제거되고 새로운 HW가 등장하기도 합니다.
예를 들면, 방금 소개한 노스브릿지와 사우스브릿지는 칩셋이라는 개념으로 통합되었으며 이후 미니 컴퓨터와 노트북, AP가 등장하는 데 기반이 되었습니다.
또, 이전 레코드로 자료를 보관하는 방식에 이어 HDD가 등장했으며, 여전히 느린 속도를 개선하기 위해 SSD가 등장했습니다. SSD는 낸드라 불리고 국내 기업인 삼성전자, 하이닉스가 주력으로 삼는 제품이기도 합니다.
CPU, Chipset, MainBoard, 주기억장치, 보조기억장치는 많이 들어본 하드웨어입니다.
우리가 주로 수행하는 작업을 담당하는 하드웨어이기도 하고, 나온지 워낙 오래되었다 보니 많은 사람들이 알고 있기 때문입니다.
특히 삼성전자와 하이닉스가 만드는 AP, RAM, SSD, HBM같은 제품들은 우리에게 익숙한 부품들입니다.
CPU는 사용자가 운영체제에 무언가의 실행 명령을 내리면 이를 스케줄러에 따라 수행하는 하드웨어입니다.
때문에 스케줄에 의한 동작. 즉 절차적 동작방식에 가장 적합한 하드웨어입니다.
하지만 요즘은 CPU보다는 GPU, NPU, DPU라는 하드웨어들이 대세가 되고 있습니다.
삼성전자는 갤럭시 S10에 세계최초로 NPU를 탑재했고, 애플도 뒤이어 자사 아이폰에 NPU를 투입했습니다.
GPU를 설계하는 회사인 엔비디아는 불과 며칠 전 애플의 시가총액을 바짝 뒤쫓았습니다.
그리고 국내에서는 DPU라는 새로운 개념이 등장했고, 이를 만드는 망고부스트라는 스타트업은 700억 단위의 투자를 받았습니다.
그렇다면 GPU, NPU, DPU는 무엇일까요?
GPU
요즘 들어 GPU는 인공지능 모델을 학습시키고 실행하는 데 필수적으로 사용됩니다.
하지만 GPU는 본래 이러한 목적으로 사용되는 하드웨어는 아니었습니다.
1999년 엔비디아는 하드웨어 가속기, 그래픽 가속기, VPU, 비디오 가속기 등이라 불렸던 하드웨어를 GPU라 통칭했습니다.
이후 다른 그래픽카드 제조사들도 GPU라는 말을 사용하기 시작했습니다.
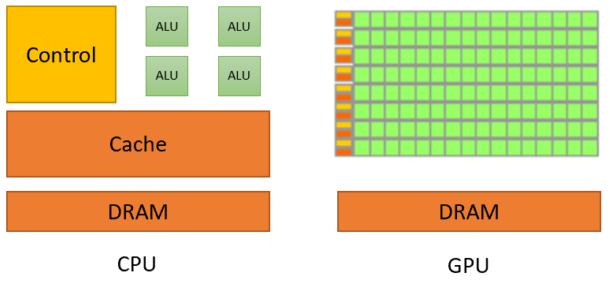
위의 그림을 보면 알 수 있듯이, CPU는 ALU의 개수가 적으나 강력한 구조를 가지고 있습니다.
때문에 하나하나의 작업단위가 큰 일을 하기 적합합니다.
GPU는 수많은 양의 작은 ALU들을 가지고 있습니다.
그렇기 때문에 작은 단위의 작업들을 많이 하는 데 있어 적합한 구조입니다.
간단한 사칙 연산을 수없이 많이 하는 과정을 예로 들어볼 수 있습니다.
CPU가 한 개의 사칙연산을 수행하는 작업을 천억 번 한다면, 이는 상당히 비효율적입니다.
스레드에 명령을 할당하고, 사칙연산을 수행하고, 스레드를 다시 할당 해제하고...
이는 사칙연산을 수행하는 작업보다 스레드 스위칭이 발생하는 오버헤드가 더 큰 상황을 초래합니다.
GPU는 조금 다르게 동작합니다.
천억 개의 사칙연산이 있지만 여러 개의 ALU가 있기 때문에, 한꺼번에 ALU개수만큼의 작업을 수행할 수 있습니다.

제품마다 다르지만, 엔비디아 GP100의 경우 3840개의 쿠다코어를 탑재하고 있습니다.
요즘 많이 사용하는 CPU들이 6코어를 갖고 있는 것을 감안했을 때, 단순 작업을 훨씬 빨리 수행할 수 있습니다.
현재 사용되는 컴퓨터 부품 중 부동소수점 연산 성능과 벡터 연산 성능이 가장 뛰어나기 때문에, 동영상 렌더링, 인코딩, 비동기 작업, 레이트레이싱, 딥러닝 등의 작업에 사용됩니다.
NPU
NPU는 Neural Processing Unit의 약자로, 기계학습에 특화된 SoC입니다.
2010년대 중반까지만 해도 기계학습을 위해서 GPU만을 사용했습니다.
이를 위해 GPGPU(General Purpose computing on Graphic Processsing Unit)라는 기술이 사용되었는데, 이는 약자에서 보면 알 수 있듯이 CPU의 작업을 단순 GPU로 옮기는 기술입니다.
이러한 GPGPU의 일환으로 만들어진 GPU 병렬처리 전용 API의 대표격이 엔비디아의 CUDA라 할 수 있습니다.
하지만 GPGPU는 기존에 비디오 카드로서 사용되던 GPU를 단순히 용도변경할 것이기 때문에 한계가 많았습니다.
우선 엔비디아만 만들 수 있기 때문에 가격이 높았고, 공급이 제한적이었습니다.
또, CPU를 데이터를 복제한 뒤 연산을 하고 결과값을 다시 CPU에 돌려주는 형식이라 비효율적이었습니다.
때문에 전성비가 낮고 레이턴시가 높은 단점을 갖고 있었습니다.
이 때문에 기계학습에 필요한 행렬곱셈, 비선형함수 등의 필수기능을 주로 탑재하고, 이외의 기능을 최소화한 정말 기계학습만을 위한 칩이 설계되었습니다.
이를 ASIC(Application-Specific Integrated Circuit)이라 하는데, 특수 목적을 위해 설계된 칩셋을 뜻합니다.
NPU도 이러한 ASIC의 일환으로, 기계학습 이외의 기능을 정말 최소로 다이어트한 물건임을 알 수 있습니다.
구글이 개발한 TPU(Tensor Processing Unit)또한 NPU의 일종으로 볼 수 있습니다.

위의 사진처럼, 기존 머신러닝을 위한 작업이 GPU에 맡겨졌다면 현재는 NPU에 맡겨지고 있습니다.
NPU는 GPU보다 기계학습 처리 효율이 훨씬 강력하기 때문입니다.
GPU는 비디오 카드로서의 역할을 동시에 수행해야 하기 때문에 화면 조사 등에 필요한 라이브러리와 API, 하드웨어가 탑재되어 있다면, NPU는 순수 기계학습만을 위해 설계된 것입니다.
DPU
DPU는 Data Processing Unit의 약자입니다.
CPU가 범용 컴퓨팅, GPU가 병렬 컴퓨팅, NPU가 기계학습을 위한 하드웨어라면, DPU는 데이터센터에서 대량의 데이터를 관리할 때 사용하는 하드웨어입니다.
인공지능 기술은 대용량의 데이터를 기반으로 하며, 학습을 위한 모델를 만들고, 파싱하고, CPU나 GPU로 전달하기 위해서 대용량 데이터 처리는 중요한 과제입니다.
이때 CPU에는 상당한 부하가 걸리는데, 이때 발생하는 오버헤드는 다음과 같습니다.
- CPU의 데이터를 지속적으로 복사해 GPU에 전달해야 한다.
- 반대로, GPU의 결과를 복사해 CPU로 전달해야 한다.
- 네트워크 데이터패킷을 계속 파싱해야 한다.
- 실시간으로 받는 데이터를 관리해줘야 한다.
- 기타 CPU와 GPU사이에 발생하는 데이터의 전/후처리를 해야 한다.
이는 클라우드 환경에서 더 주목되는 문제로, 네트워크/데이터 파이프라인을 CPU가 관리해 오버헤드가 발생하는 개념이라 볼 수 있습니다.
DPU는 이러한 처리를 전담해 CPU의 부담을 줄일 뿐 아니라 네트워크/데이터 파이프라인을 독립시킬 수 있어 보안 측면이 부각된 개념이라 할 수 있습니다.
정리
이번 포스트에서는 컴퓨터를 구성하는 주요 하드웨어들을 알아보았습니다.
특히, 요즘 부각되는 GPU, NPU, TPU, DPU의 차이를 알아봄으로, 앞으로 개발자 또는 연구자들의 대화에 좀 더 쉽게 끼어들 수 있을 것입니다.
다음 포스트에서는 조금씩 더 자세한 내용을 확인할 수 있도록 하겠습니다.